Large scale systems

These systems are characterized by having a large number of components that work in a coordinated way (most of them remotely), often distributed over a wide area, and in which resources are limited. As a control objective of these systems, apart from ensuring that each component of the process works properly according to predefined conditions, it is required to plan the operation strategy so that, depending on the available resources, certain demands can be met. This is for example the case of water distribution systems or hydraulic resources of a basin.
To solve this problem, the research group has proposed three lines of work in this areas:
Strategies for data validation and reconstruction
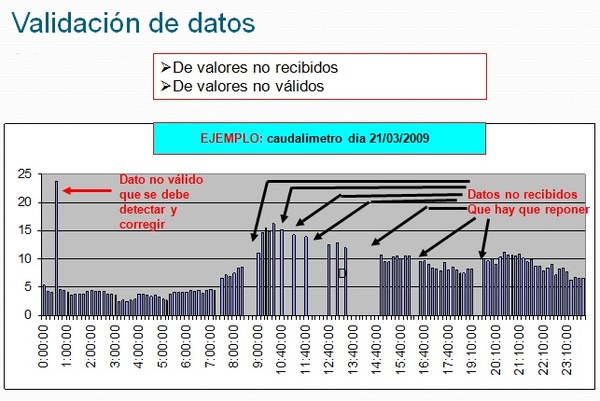 |
The data validation consists of capturing the data with a fixed time frequency (for example hourly) from the operational database of the remote control system, which allow to know the state of the network, periodically (once a day) or by express request of the remote control system operator, analyze with different test levels all the data of the interval in question and of the result obtained label the data as valid data specifying the passed or invalid tests specifying the validation test not passed and store them in the same operational database of the remote control system. |
The set of tests that each of the data must pass with a fixed frequency (ten-minute, hourly or daily) of the state of the network is inspired by the data quality levels of the automatic weather stations defined in the UNE standard 500540.
-
- Test 1. Communication errors: it is about knowing whether the data has arrived at the expected instant or not (ten-minute, hourly or daily).
- Test 2. It is analyzed if a data exceeds the physical maximum or minimum values that are impossible to exceed for a coherent data.
- Test 3. The temporal variation of the data is analyzed, since the difference between two consecutive values must not exceed some reference values.
- Test 4. It is analyzed if the sensors of the same station are consistent with each other. For example, if the position of a valve indicates that it is closed, no water can circulate and the flow sensor should read zero or a value very close to zero.
- Test 5. The spatial coherence of the network data is analyzed based on a model of the relationship between measurements and the temporal coherence of the data is analyzed and the estimate of the data is compared based on its history with the data to be validated.
- Test 1. Communication errors: it is about knowing whether the data has arrived at the expected instant or not (ten-minute, hourly or daily).
If a data does not pass any of these tests, the data is not reliable and must be reconstructed by applying one or more models (analytical redundancy) that allow its value to be estimated.
This methodology has already been implemented in the Barcelona distribution network which has 400 flow meters and is currently implemented with hourly and daily data from the ATLL water transport network. It is considered that it will be a great benefit to increase confidence in the data of the remote control system and its subsequent exploitation to carry out a correct management of the network, such as the calculation of the hydraulic performance of the different sectors of the network and/or the detection of leaks in the same.
Model-Based Predictive Control (MPC) has proven to be one of the widely accepted advanced control techniques for large-scale system control. Applied to different large-scale infrastructures such as drinking water networks, sewage networks, open channel networks, or electrical networks, this technique confirms the applicability of this technique. The main reason is that once the dynamic model of the plant is obtained, the MPC design consists only of expressing the desired performance specifications through different control objectives (for example, weights on tracking errors and actuation efforts as in classical linear quadratic regulation) and constraints on system variables (for example, min/max of selected process variables and/or their rates of change) that are necessary to ensure process safety and asset health.
The rest of the MPC design is automatic: the given model, constraints, and weights define an optimal control problem over a finite time horizon in the future (this is why the approach is called predictive). This translates into an equivalent optimization problem and is solved online to obtain an optimal sequence of future control moves. Only the first of these moves is applied to the process, as in the next step it solves a new optimal control problem to exploit information from new measurements. In this way, an open-loop design methodology (optimal control) is transformed into a feedback one.
However, the main obstacle for MPC control, like any other control technique, when applied to large-scale systems in a centralized manner, is scalability. The reason is that a huge control model is needed, which is difficult to maintain or update and has to be rebuilt at every change in the system configuration, such as when some part of the system has to be interrupted due to maintenance actions or malfunctions. Later, a model change would require re-tuning the centralized controller. Clearly, the cost of establishing and maintaining the monolithic solution to the control problem is prohibitive. One way to circumvent these problems could be to investigate decentralized MPC (DMPC) or distributed MPC techniques, where local networked MPC controllers are responsible for controlling part of the entire system. The main difference between decentralized and distributed MPC is that the latter requires negotiations and recomputations of local control actions within the sampling period to increase the level of cooperation.
- PLIO/SOSTAQUA/WIDE:: application to drinking water networks
- CORAL/OPTIMAR: application to sewer networks
- GERHYCO/PREDO/HIDROPTIM: application to irrigation systems
As a result of these projects, several software tools have been developed that allow the MPC control to be implemented in real time.
Share: